Clean Architecture with Nest.js
March 28, 2025
규모 있는 소프트웨어 개발을 하다보면 필연적으로 다음과 같은 문제들에 마주합니다.
"영향을 받는 곳이 너무 많아 수정이 힘들다" "인원이 늘어나도 생산성이 그닥 높아지지 않는다."
Clean Architecture는 코드 간 의존성을 줄여 코드의 유지 보수성을 높이고, 변경을 유연하게 합니다.
최종적으로는 아주 적은 인력으로도 시스템을 유지, 보수, 확장 할 수 있게 됩니다.
이 포스팅은 Clean Architecture 책을 기반으로, 제가 경험해본 Clean Architecture에 관한 글입니다. 모든 예시는 Typescript와 Nest.js 기반입니다.
의존
왜 코드 규모가 커지면 점점 수정, 확장이 어려워질까요? 이를 이해하기 위해 먼저 의존이라는 개념을 이해해야 합니다.
Module
우리는 코드를 작성할 때, 하나의 파일에 모든 코드를 작성하지 않습니다. Java의 import, Javascript의 import, require, c, c++의 include 같은 코드를 통해 외부 라이브러리, 혹은 다른 모듈의 코드를 불러오게 됩니다.
바로 이 부분에서 코드들 간의 의존성이 생기게 됩니다.
일례로, 어떤 프로젝트에 A모듈, B모듈만 존재한다고 가정해봅시다. 이 때, A모듈에서는 B모듈을 import 해서 사용하고 있습니다.
불안정한 Module
아무도 A모듈을 import하지 않지만, A모듈은 B모듈의 코드를 사용하고 있습니다. 이 때, A 모듈의 코드를 변경하면 어떨까요?
A모듈에서 코드를 아무리 수정해도, 어떤 코드도 영향을 받지 않습니다. 즉, A 모듈은 수정에 자유롭습니다. 우리는 이런 상태를 "불안정하다" 라고 합니다.
안정적인 Module
반면, B 모듈은 A 모듈에서 호출되지만, 아무 모듈도 import하지 않습니다. B모듈의 코드를 수정하면 어떻게 될까요? B모듈의 수정에 따라, A 모듈까지 수정해야 할 경우가 생길 것입니다.
즉, B모듈은 수정이 자유롭지 않습니다. 우리는 이런 상태를 "안정적이다" 라고 합니다.
그렇다면 모든 모듈이 안정적이면 좋을까요? 그럼 코드를 수정할 수 없으므로 좋지 않습니다. 그럼 모든 모듈이 불안정하면 좋을까요? 좋겠지만 이는 불가능합니다.
어떤 모듈이 불안정해지면 어떤 모듈은 안정적이게 됩니다. 따라서 우리는 코드를 불안정한 모듈과 안정한 모듈로 분리해야 합니다.
추상화와 구체화
잠시 이야기를 넘어와 봅시다.
다음과 같은 코드를 본 적 있을겁니다.
interface Logger {
log(message: string): void;
}class ConsoleLogger implements Logger {
log(message: string): void {
console.log(`[Console] ${message}`);
}
}interface를 만들고, 그 interface에 맞는 class를 구현 했습니다.
이 코드에서 userProcessor은 추상화 부분, AdminUserProcessor은 구체화 부분이라 부릅니다.
왜 굳이 코드를 이렇게 나눌까요? 그건 바로 인터페이스(추상화 부분)은 안정적이고, 구현체 부분은 불안정하기 때문입니다.
추상화를 통한 의존성 제어
이제 두 가지 개념을 응용해봅시다.
아까와 같이 A모듈에서 B모듈을 호출하려 합니다. 그런데 만약, B모듈이 추상화된 코드를 가지고 있다고 생각해봅시다.
A모듈에서 B모듈의 추상화를 import하여 사용하면 어떨까요? 추상화는 안정적이기 때문에 이는 매우 자연스럽습니다. 추상화된 코드는 변경이 거의 없기 때문에 A모듈이 수정에 영향을 받을 일이 잘 없을 것입니다.
이런 식으로 코드의 모든 의존을 추상화에 하면 어떨까요? 우리는 구현체를 자유롭게 수정하면서 코딩할 수 있을 것입니다.
이 개념이 바로 "의존성 제어"입니다. 위의 이미지와 같이 의존성의 방향을 바꾸어 설계할 수 있습니다.
이제 안정적인 부분을 추상화로, 불안정한 부분을 구현체로 코드를 나누는 것에 성공했습니다.
이는 매우 이상적이지만 한가지 함정이 존재합니다. 추상화에 의존한다면, 구현체 코드는 모르는것 아닌가요? 실제 코드의 동작은 구현체가 할텐데, 추상화를 import해서 사용하면 코드가 동작하질 않습니다.
의존성 주입
그래서 필요한 개념이 바로 Dependency Injection(DI), 의존성 주입입니다. 추상화에 의존하는 모듈들에게, 구현체의 내용을 알려주는 것이죠.
그럼 어떤 방법으로 의존성을 주입할 수 있을까요?
위의 예시를 다시 가져와서 알아봅시다.
interface Logger {
log(message: string): void;
}class ConsoleLogger implements Logger {
log(message: string): void {
console.log(`[Console] ${message}`);
}
}생성자 주입
클래스가 생성될 때 필요한 의존성을 전달 받습니다.
class UserService {
constructor(private logger: Logger) {}
registerUser(username: string) {
this.logger.log(`유저 등록 완료: ${username}`);
}
}
// 사용 예시
const logger = new ConsoleLogger();
const userService = new UserService(logger);
userService.registerUser('홍길동');코드를 보면, 클래스에서는 Logger 인터페이스만 사용하지만 외부에서 생성할 때 Logger의 내용을 주입해줍니다.
메서드 주입
메서드를 호출할 때마다 의존성을 전달해줍니다. 매번 다른 의존성을 유연하게 전달할 수 있지만, 코드가 복잡해집니다.
class UserService {
registerUser(username: string, logger: Logger) {
// 유저 등록 로직
logger.log(`유저 등록 완료: ${username}`);
}
}
// 사용 예시
const userService = new UserService();
const logger = new ConsoleLogger();
userService.registerUser('홍길동', logger);Setter 주입
의존성이 필요한 곳에 Setter를 만들어 나중에 선택적으로 주입합니다.
class UserService {
private logger?: Logger;
setLogger(logger: Logger) {
this.logger = logger;
}
registerUser(username: string) {
if (this.logger) {
this.logger.log(`유저 등록 완료: ${username}`);
} else {
console.log('Logger가 없습니다.');
}
}
}
// 사용 예시
const userService = new UserService();
userService.setLogger(new FileLogger());
userService.registerUser('홍길동');어디서 의존성을 주입할까?
의존성을 주입하는 다양한 방법을 알았습니다. 그러나 한가지 또 고민이 생깁니다. 어디서 의존성을 주입해줘야 할까요? 의존성을 주입해주기 위해선 구현체 코드를 호출해야 하는데, 어떻게 보면 구현체에 의존하게 된다고 볼 수 있습니다.
그래서 보통 의존성 주입은 "main" 컴포넌트에서 전부 처리합니다. 이름이 main이 아니어도, 프로그램의 entry point가 그 역할을 하게 됩니다.
이렇게 하면 얻는 이점은 다음과 같습니다.
- 한 곳에서 객체를 생성하여 중앙 집중화 한다.
- 의존성의 흐름이 명확해진다.
- 구현체에 의존하는 것을 main이 혼자 맡을 수 있다.
Main은 전체 애플리케이션의 시작점이기 때문에, 여기서 구현체에 의존하고 구현체를 결정하는건 자연스럽습니다.
비즈니스 로직이 있는 곳에서 구현체에 의존하면 다시 설계의 유연성이 무너지게 될 것입니다.
프레임워크
추가적으로, Nest.js와 Spring과 같은 프레임워크는 의존성 제어를 간편하게 할 수 있게 도와줍니다.
의존성 제어
이제 우리는 추상화를 이용해, 코드의 의존성을 제어할 수 있는 능력을 갖췄습니다.
그렇다면 이제 어떻게 코드의 의존성을 설계할 것인지에 대해 알아봐야 합니다.
의존성 방향
Clean Architecture에서는 코드의 의존성 방향을 어떻게 설계해야 하는지 제시합니다.
아래는 아키텍처에 관심이 있다면 한번쯤 봤을법한 이미지입니다.
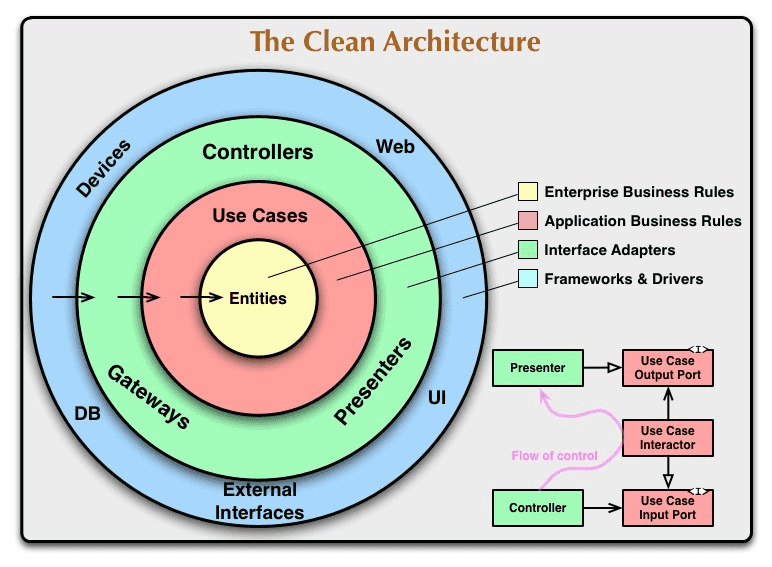 위 그림에서 요소를 크게 분리해보자면, 엔티티, 유즈케이스, 어댑터, 세부사항 정도로 나눌 수 있습니다.
위 그림에서 요소를 크게 분리해보자면, 엔티티, 유즈케이스, 어댑터, 세부사항 정도로 나눌 수 있습니다.
세부사항 -> 어댑터 -> 유즈케이스 -> 엔티티
와 같은 방향을 따르고, 내부 원에 속한 요소는 외부 원에 대해 어떤 것도 알지 못해야 합니다.
요소 각각에 대해 한번 알아봅시다.
엔티티
애플리케이션의 핵심 중의 핵심이 되는 업무 객체입니다. 예들 들어, 배달 서비스라면 음식점과 주문자 의 존재 정책이 엔티티가 될 수 있습니다.
유즈케이스
유즈케이스는 애플리케이션의 핵심 업무 객체입니다. 앤티티는 애플리케이션이 없어도 존재해야 하지만, 유즈케이스는 애플리케이션에서 제공하는 기능입니다. "예를 들면, 장바구니에 음식을 담는다"와 같은 행위입니다.
어댑터
유즈케이스가 작동하기 위해서는, 사용자 인터페이스, 데이터베이스와 소통해야 합니다. 유즈케이스가 GUI와 데이터베이스 사이에서 브릿지 역할을 해 주는 것이 어댑터 레이어입니다. Controller와 같은 코드들이 어댑터가 될 수 있습니다.
세부사항
웹, 데이터베이스, 프레임워크 등입니다. 그리고 언제든지 바뀔 수 있는 것들입니다. 예를 들면, 데이터베이스를 MongoDB에서 MySQL로 바꿔야 할 수 있습니다.
클린 아키텍처를 적용하면 이런 세부사항의 결정을 끝까지 미룰 수 있고, 언제든 바꿀 수 있습니다.
이미지의 오른쪽 아래 그림을 살펴봅시다.
Controller에서 입력이 들어오면, 그걸 use case로 전달하여 처리하고, presenter로 전송하는게 자연스럽습니다.
그러나 이를 위해서는 UseCase가 Presenter를 알아야 합니다. 내부 원이 바깥쪽 요소를 알지 않아야 한다는 철학을 지키기 위해, 우리는 의존성 역전 개념을 사용하여, UseCase가 Presenter에 의존하지 않게 만들 수 있습니다.
이런식으로 의존성 흐름을 제어하여 위 이미지와 같은 의존 흐름을 만드는 것이 Clean Architecture의 기본 개념입니다.
코드를 통해 Clean Architecture를 설계해보자
제가 운영중인 서비스에는 단순한 채팅 기능이 있습니다. 이 모듈이 단순한 Entity를 유지하고 있으므로, 예시로 사용해보겠습니다.
아래 코드에서 확인할 부분은 데이터베이스 의존성을 제거한 부분입니다. 엔티티의 정의와 세부사항을 정하는 코드를 확인해보면 좋습니다.
엔티티를 정의하자
서비스를 만들 때, 가장 먼저 Entity를 설계해야 합니다. Entity는 애플리케이션이 존재하지 않아도 존재해야 합니다.
채팅 기능이라면, 아래와 같은 Entity를 가질 수 있습니다.
/entities/Chat.ts
export type ChatStatus = 'normal' | 'inactive' | 'deleted';
export interface ChatProps {
user1: string | IUser;
user2: string | IUser;
status?: ChatStatus;
contents: ContentProps[];
}
export class Chat {
private props: {
user1: string | IUser;
user2: string | IUser;
status: ChatStatus;
contents: Content[];
};
constructor(props: ChatProps) {
this.props = {
user1: props.user1,
user2: props.user2,
status: props.status ?? 'normal',
contets: (props.contents ?? []).map((c) => new Content(c)),
};
}
//getter
addContent(contentProps: ContentProps) {
const content = new Content(contentProps);
this.props.contents.push(content);
}
// 도메인 엔티티 -> DTO or primitive 변환
toPrimitives(): ChatProps {
return {
user1: this.props.user1,
user2: this.props.user2,
status: this.props.status,
contents: tis.props.contents.map((c) => c.toPrimitives()),
};
}
}/entities/Content.ts
export interface ContentProps {
userId: string;
content: string;
}
export class Content {
private props: Required<ContentProps>;
constructor(props: ContentProps) {
this.props = {
userId: props.userId,
content: props.content,
};
}
get userId(): string {
return this.props.userId;
}
get content(): string {
return this.props.content;
}
toPrimitives(): ContentProps {
return { ...this.props };
}
}먼저, Chat은 하나의 채팅방 역할을 합니다. 다음으로 Content는 채팅방에서 하나하나의 채팅을 의미합니다.
엔티티를 설계할 때는 Entity가 가지는 필수 요소를 정의하고, 생성자를 정의합니다. 이 때 생성자에서 데이터 무결성을 위한 검사를 할 수 있습니다.
그리고, addContent와 같은 데이터 무결성을 위한 약간의 비즈니스 로직이 포함될 수 있습니다. 이 부분도 완전히 제거하는 편이 좋을 수 있는데, 저는 포함하여 사용중입니다.
유즈케이스를 정의하자
유즈케이스는 service 코드를 정의하여 사용하고 있습니다.
export class ChatService {
constructor(
//repository DI
@Inject(ICHAT_REPOSITORY)
private readonly chatRepository: IChatRepository,
...
) {}
async getChat(userId: string) {
const token = RequestContext.getDecodedToken();
const user1 = token.id > userId ? userId : token.id;
const user2 = token.id < userId ? userId : token.id;
const chat = await this.chatRepository.findByUser1AndUser2WithUser(
user1,
user2,
);
if (!chat)
throw new NotFoundException(`can't find chat ${user1} and ${user2}`);
const opponent =
(chat.user1 as IUser)._id == token.id
? (chat.user2 as IUser)
: (chat.user1 as IUser);
const conversationForm = { opponent, contents: chat.contents };
return conversationForm;
}데이터베이스에 접근하는 코드를 의존성 주입하여 사용하고 있습니다. getChat에서 비즈니스 로직을 수행하고, 결과를 반환합니다.
어댑터를 정의하자.
어댑터로는 Controller를 사용하고 있습니다. 클라이언트의 입력을 Service로 전달해줍니다.
@Controller('chat')
export class ChatContoller {
constructor(private readonly chatService: ChatService) {}
@Get()
async getChat(@Query() getChatDTO: GetChatDTO) {
const { toUid } = getChatDTO;
return await this.chatService.getChat(toUid);
}
}크게 확인할 부분은 없습니다.
세부사항을 정의하자
여기에서 말하는 세부사항은 어떤 DB를 쓸 것인가? 와 같은 문제입니다. 저는 MongoDB를 사용할 것인데, 나중에 MySQL과 같은 DB로 옮길것을 대비해서 DB의 의존성을 제거하고 싶습니다. 다음과 같이 해 볼 수 있습니다.
먼저 Service 코드에서 MongoDB에 접근하는 코드를 직접 호출하면, service 코드가 세부사항을 알아야 하므로, Clean Architecture가 지켜지지 않습니다.
따라서 의존성을 역전시키기 위한 interface를 정의해줍니다.
export interface IChatRepository {
findByUser1AndUser2WithUser(
user1Id: string,
user2Id: string,
): Promise<Chat | null>;
// 나머지 코드
}구현체도 만들어줍시다.
export class ChatRepository implements IChatRepository {
constructor(
@InjectModel('Chat')
private readonly ChatModel: Model<IChat>,
) {}
async findByUser1AndUser2WithUser(
user1Id: string,
user2Id: string,
): Promise<Chat | null> {
const doc = await this.ChatModel.findOne({
user1: user1Id,
user2: user2Id,
}).populate('user1 user2');
if (!doc) return null;
return this.mapToDomain(doc);
}
private mapToDomain(doc: IChat): Chat {
const chat = new Chat({
user1: doc.user1,
user2: doc.user2,
status: doc.status,
contents: doc.contents.map((c) => ({
userId: c.userId,
content: c.content,
createdAt: c.createdAt.toString(),
})),
});
return chat;
}
}구현체에서 주의해야 할 부분은, Repository는 Entity를 반환해야 한다는 점입니다. Entity가 아닌 DB에서 읽은 데이터를 그대로 반환한다면, 그 코드를 사용하는 Service는 결국 DB에 의존하게 되어버립니다.
이제 DB를 MySQL로 바꾸고 싶다면 어떻게 할까요? ChatRepository대신 MySQLChatRepository를 작성하고, 의존성 주입을 해주면 끝입니다. 다른 모듈은 ChatRepository에 직접 의존하지 않으므로 변경에 영향을 받지 않습니다.
Clean Architecture를 어떻게 더 적용해볼까?
지금까지 간단한 코드로 어떤 느낌으로 DB의존성을 제거하는지 살펴보았습니다.
의존성을 제어하는 방법을 잘 사용한다면, 더 다양한 세부사항에 대한 결정을 미룰 수 있습니다.
예를 들면, 결제 기능을 구현할 때 Interface를 정의해둔다면 어떤 결제 서비스를 이용할지 와 같은 결정은 멀리 미뤄둘 수 있습니다.
코드들이 추상화에만 의존하게 되니 변경도 훨씬 자유로울것이고, 유지보수 역시 훨씬 편해질 것입니다.
즉, 처음에 우리가 달성하고자 했던 목표를 많이 달성했습니다.
이 포스팅에서 설명한 내용이 전부는 아닙니다. FP, OOP등도 적용하고, SOLID 원칙 같은것도 적용하면 더 좋은 코드를 만들 수 있습니다.
저도 처음부터 클린아키텍처를 적용하며 서비스를 만들었으면 좋았겠지만, 당시에는 이런 개념을 몰랐었기에 이제서야 하나씩 리팩토링 해 가고 있습니다.
앞으로도 다양한 개념들을 적용하며, 더 나은 구조에 대해 탐구해보겠습니다.